
正则表达式
1. 正则表达式分类
正则表达式:REGEXP,REGular EXPression。
正则表达式分为两类:
- Basic REGEXP(基本正则表达式)
- Extended REGEXP(扩展正则表达式)
2. 基本正则表达式
//元字符
. //任意单个字符
[] //匹配指定范围内的任意单个字符
[^] //匹配指定范围外的任意单个字符
//匹配次数(贪婪模式)
* //匹配其前面的任意单个字符任意次
.* //任意长度的任意字符
\? //匹配其前面的任意单个字符1次或0次
\+ //匹配其前面的任意单个字符至少1次
\{m,n\} //匹配其前面的任意单个字符至少m次,至多n次
//位置锚定
^ //锚定行首,此字符后面的任意单个字符必须出现在行首
$ //锚定行尾,此字符前面的任意单个字符必须出现在行尾
^$ //空白行
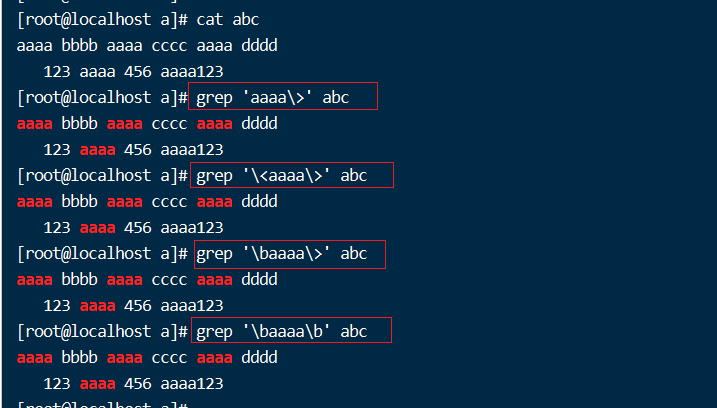
\<或\b //锚定词首,其后面的任意单个字符必须作为单词首部出现
\>或\b //锚定词尾,其前面的任意单个字符必须作为单词尾部出现
/分组
\(\)
例:\(ab\)*
//后向引用
\1 //引用第一个左括号以及与之对应的右括号所包括的所有内容
\2 //引用第二个左括号以及与之对应的右括号所包括的所有内容
表达式用法
// .点 任意单个字符
[root@localhost a]# ls | grep '^.$' 一个字符就是一个点,^表示开始,$表示结束
a
b
[root@localhost a]# ls | grep '^..$'
aa
bb
,,,
//[]中括号匹配指定范围内的任意单个字符
[root@localhost a]# ls |grep '^[ab12]$' 里面写的什么就显示什么
1
2
a
b
[root@localhost a]# ls |grep '^[a-d]$' 显示字母a到d
a
b
c
d
[root@localhost a]# ls |grep '^[1-3a-d]$'
1 '-'放在开始的时候表示 '-' 本身, '-'放在两个不同类型的中间表示本身,放到后面也表示本身
2
3
a
b
c
d
[root@localhost a]# ls |grep '^[-1,9]$'
,
-
1
9
[root@localhost a]# ls |grep '^[-1,9a-c]$'
,
-
1
9
a
b
c
[root@localhost a]# ls |grep '^[-1,9a-cl"15"]$'
"
,
-
1
5
9
a
b
c
l
// [^]匹配指定范围外的任意单个字符
[root@localhost a]# ls |grep '^[1-3]$' 这是没有加 ^
1
2
3
[root@localhost a]# ls |grep '^[^1-3]$' 取反,表示除了1-3其余都显示出来
"
,
-
4
5
[root@localhost a]# ls |grep '^[1^3^]$' ^必须放在中括号里面的最前面才表示取反
^
1
3
// *匹配其前面的任意单个字符任意次
[root@localhost a]# ls | grep '^ab*$'
a
ab
abb
abbb
abbbb
abbbbbb
[root@localhost a]# ls | grep '^ab*cd$'
abbbbbbcd
abbbbbcd
abbbbcd
abbcd
[root@localhost a]# ls | grep '^\]ab\[$' 加\转义表示本身
]ab[
[root@localhost a]# ls | grep '^a*b*c*$'
a
aa
b
c
abbbbbbb
abc
abcccccc
// .*任意长度的任意字符
[root@localhost a]# ls | grep '^a.*$' 显示a开头的
a
aa
ab
ababab
abababcab
abb
[root@localhost a]# ls | grep '^a.*$' | xargs rm -f 删除a开头的文件
[root@localhost a]# ls | grep '^a.*$'
[root@localhost a]#
// \?匹配其前面的任意单个字符1次或0次
[root@localhost a]# ls |grep '^abc\?$'
ab
abc
// \+匹配其前面的任意单个字符至少1次
[root@localhost a]# ls |grep '^ab\+$'
ab
abb
abbbb
// \{m,n\}匹配其前面的任意单个字符至少m次,至多n次
[root@localhost a]# ls |grep '^ab\{0,2\}$' 表示b最少为0次最多为2次
a
ab
abb
[root@localhost a]# ls |grep '^ab\{2\}$' 表示b就两次,注意大括号要转义
abb
// ^和$
^ //锚定行首,此字符后面的任意单个字符必须出现在行首,$ //锚定行尾,此字符前面的任意单个字符必须出现在行尾
[root@localhost a]# ls |grep 'ab\{2\}' 这里没有加^和$,第一个和第三个不是全部都匹配到
aabb 第一个a没有匹配的
abb 全部匹配到了
abbbb 最后两个bb没有匹配到
[root@localhost a]# ls |grep '^ab\{2\}$' 这里加了^和$,就只显示全部都匹配到的
abb
// ^$ 空白行
[root@localhost a]# vim abc
[root@localhost a]# cat abc
aaaa
//这里有一个空行
bbb
[root@localhost a]# grep '^$' abc
//过滤出了这个空行
[root@localhost a]# grep -v '^$' abc // -v取反,除了空行的其余都显示出来
aaaa
bbb
[root@localhost a]# cat abc
aaaa
#bbb
[root@localhost a]# grep -v '^$' abc |grep -v '^#' //除了空行和带#注释的,其余都显示出来
aaaa
// \<或\b
\<或\b //锚定词首,其后面的任意单个字符必须作为单词首部出现
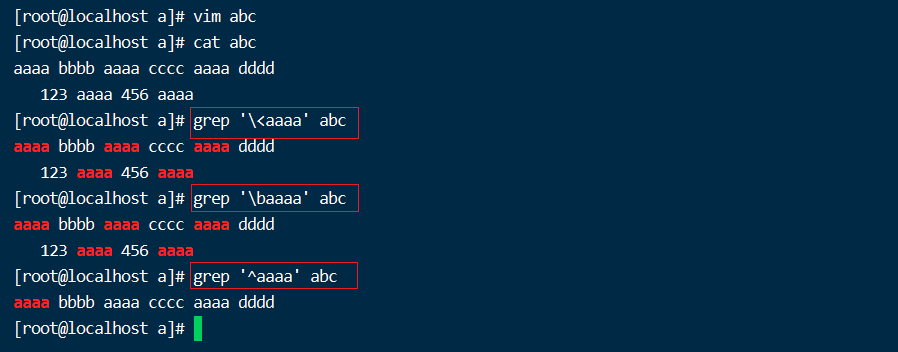
\>或\b //锚定词尾,其前面的任意单个字符必须作为单词尾部出现
// \(ab\)*
[root@192 a]# ls | grep '^\(ab\)*$'
ab
abab
ababab
abababab
\1 //引用第一个左括号以及与之对应的右括号所包括的所有内容
\2 //引用第二个左括号以及与之对应的右括号所包括的所有内容
[root@192 a]# echo 'aaaa 456 aaaa123' | sed 's/aaaa \(.*\) \(.*\)/aaaa \2 \1/'
aaaa aaaa123 456
3. 扩展正则表达式
//字符匹配
. //匹配任意单个字符
[] //匹配指定范围内的任意单个字符
[^] //匹配指定范围外的任意单个字符
//次数匹配
* //匹配其前面的任意单个字符任意次
? //匹配其前面的任意单个字符1次或0次
+ //匹配其前面的任意单个字符至少1次
{m,n} //匹配其前面的任意单个字符至少m次,至多n次
//位置锚定
^ //锚定行首,此字符后面的任意单个字符必须出现在行首
$ //锚定行尾,此字符前面的任意单个字符必须出现在行尾
^$ //空白行
\<或\b //锚定词首,其后面的任意单个字符必须作为单词首部出现
\>或\b //锚定词尾,其前面的任意单个字符必须作为单词尾部出现
//分组
() //分组
\1,\2,\3,....
例:(ab)*
//后向引用
\1 //引用第一个左括号以及与之对应的右括号所包括的所有内容
\2 //引用第二个左括号以及与之对应的右括号所包括的所有内容
//或者
| //or 默认匹配|的整个左侧或者整个右侧的内容
//例:C|cat表示C或者cat,要想表示Cat或者cat则需要使用分组,如(C|c)at